As I talked in one of my previous blogs, Regression is a type of Supervised Machine Learning where given a set of Input features, underlying algorithm returns a continuous valued output. Let’s take an example to understand it better:

In the above data-set, we are providing number of Independent features like house size, number of bedrooms, number of floors, number of bathrooms and age of the house. On the right most column is the actual price, the house was sold. This is generally called target or output. When a similar data-set is provided to an appropriate learning algorithm and after the learning phase is complete, we would expect the algorithm to predict the expected selling price of a house with similar features. One of a typical requirements is mentioned in the last row of the above data-set. As you can imagine, depending upon the values of input features like house size, bedrooms, age etc, the price of the house can be anywhere between 100K USD to 1 Million USD. That’s the reason of it being also called a Continuous Valued output.
Some of the common use-cases of Regression can be predicting population of a city, Sensex Index, Stock Inventory and many more. In-Fact Regression is one of the earliest forms of Statistical analysis and also one of the most widely used Machine Learning techniques.
In this blog, we will try to implement the simplest form of Regression referred as Linear Regression. For any Machine Learning algorithm, a typical work-flow looks like :

We provide Training Data-Set to a given Algorithm. It uses a Hypothesis which is essentially a mathematical formula to derive inferences about the data-set. Once the hypothesis has been formulated, we say that Algorithm has been trained. When we provide to algorithm a set of Input features, it return us an Output based upon its hypothesis. In the above scenario, we would provide details about House Size, Number of Bedrooms, Number of Floors, Number of Bathrooms and Age to the algorithm it in-turn would respond us with an expected price the house can fetch in the market.
Let’s see what can be the hypothesis / formula for our scenario. For easier understanding, let’s simplify the context a bit and think about having only house size as a single input feature against which we need to predict house prices. If we plot both these variables on a graph, it would look something like:

If we can draw a straight line across the points, then we should be able to predict the values of houses when different sizes are provided as inputs. Let’s take a look at different lines we can draw on the above graph:

The line which touches or is quite close to as many points as possible on the graph is most likely to provide us the best predictions while the line which touches least or is far from a majority of points is likely to provide us worst predictions. In our case line h1 appears to be the best possible scenario. The ability to draw such a straight line across a given data-set is in-essence the goal of any Linear Regression Algorithm. As we are attempting to draw a straight line, we call it a Linear Regression solution. In Mathematical terms, we can formulate our hypothesis as follows:

where  is the initial constant value we choose and
is the initial constant value we choose and  is the value we will multiple by a given house size. The goal of our hypothesis is to find values of and in such a way that difference between actual values provided in our training data-set and predicted values is minimum. Again if we have to represent it in mathematical terms, the formula would be :
is the value we will multiple by a given house size. The goal of our hypothesis is to find values of and in such a way that difference between actual values provided in our training data-set and predicted values is minimum. Again if we have to represent it in mathematical terms, the formula would be :

where and are the chosen parameters, m is the number of rows in our training data-set and  is the predicted value for ith element in our training data-set and
is the predicted value for ith element in our training data-set and  is the actual target value of ith element in our training data-set. In Machine Learning terminology, this function is popularly referred as Cost Function or Squared Error Function as well. Let’s take couple of examples to understand the functioning better:
is the actual target value of ith element in our training data-set. In Machine Learning terminology, this function is popularly referred as Cost Function or Squared Error Function as well. Let’s take couple of examples to understand the functioning better:
Continue reading →







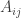 where i is number of row and j is number of column. So in examples above,
where i is number of row and j is number of column. So in examples above,  (Matrix) will be 4 and
(Matrix) will be 4 and  (Vector) will be 5.
(Vector) will be 5.


